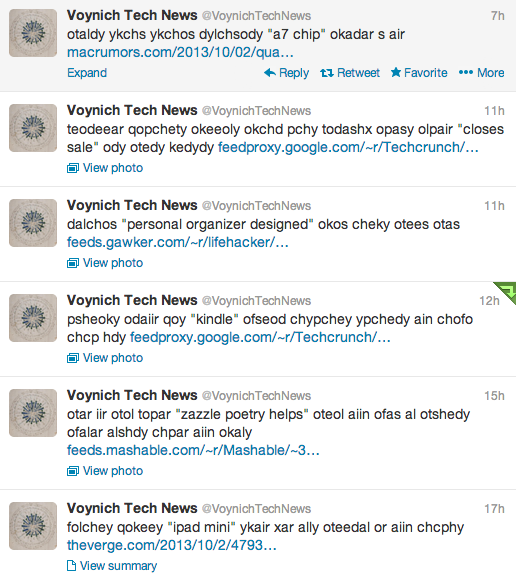
I made a Twitter bot called Voynich Tech News. Every few hours it posts a link to a technology news blog along with a random snippet of text from a transcription of the Voynich manuscript, interspersed with randomly extracted noun phrases from the title of the blog post. The intention is to make it seem like the Voynich text is reporting/commenting on/elaborating on the blog post it links to.
I made this weird bot for a number of reasons.
First off, I discovered this transcript of the Voynich manuscript recently and found it fascinating. (Here’s a link to the full, uncompressed text.) The manuscript itself is beautiful, of course, but because the symbols are unfamiliar, it’s hard to get a sense of what the text “feels” like, from a structural and statistical perspective. Looking at the transcript, you instantly understand that the symbols aren’t just random gibberish—there’s a discernable, language-like structure. I wanted to bring the transcript to other people’s attention, and I wanted to do something creative with it so I could understand it better.
Second, and this is a bit of a stretch, I wanted to help decipher the script. The Voynich manuscript is famously undeciphered, and it’s debatable whether it even represents language at all. It could be steganography, or an elaborate cipher, or graphic glossolalia. (Wikipedia has a good overview of the various theories.) Deciphering a script is easier when you find a sample of that script in a new context. Although there’s no “new” text being posted to @VoynichTechNews—it’s all drawn verbatim from the transcript, except for the interjected bits of tech news—my hope is that seeing the text do something new, juxtaposed with something unexpected, might jostle something loose in someone’s brain and bring about an epiphany about how the script is structured, and what it might mean.
Oh, and I wanted to have some fun at the expense of people who obsess over technology news on Twitter.
Technical notes: I used TextBlob to extract “noun phrases” from blog post titles. The parsing is imperfect so sometimes it looks like it’s just “random substrings” rather than “noun phrases,” but that serves the aesthetic just as well. My procedure for extracting text from the Voynich transcript was to take the first complete transcription of each line, strip whitespace (marked as ‘-’ and ‘=’ etc. in the transcript), and put it into a big text file. To compose the tweet, I choose a random stretch of words from that file. The words in the tweet therefore might consist of stretches of text that might not be contiguous in the actual manuscript (if, for example, two lines next to each other in my text file are actually found on different pages in the MS).
Reply
You must be logged in to post a comment.
No comments
Comments feed for this article
Trackback link: http://www.decontextualize.com/2013/10/voynich-tech-news/trackback/